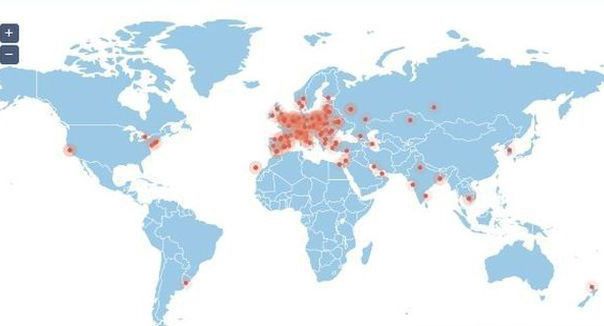


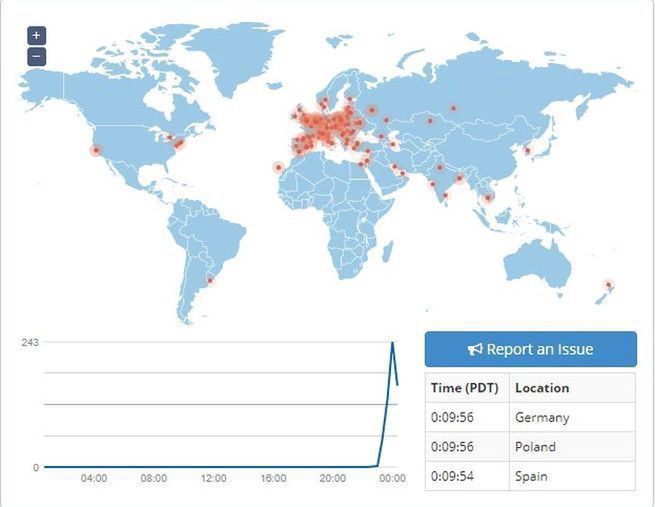
Do awarii, która sparaliżowała dużą część internetu, przede wszystkim na obszarze Europy doszło w czwartek rano. Wiele stron i serwisów internetowych okazało się niedostępnych, częstym przypadkiem była niemożność wysłania i odbioru e-maili, a także skorzystania z internetowych usług.
Szybko okazało się że awarią zostały dotknięte te serwisy i platformy, które korzystają z usług hostingowych firmy OVH, jednego z najbardziej znanych w regionie dostawców tego typu rozwiązań.
Awaria dała o sobie znać przez większą część dnia, a OVH na bieżąco relacjonowało postępy nad przywróceniem sprawności wszystkich systemów w mediach społecznościowych.

Ostatecznie dostawcy w czwartek wieczorem udało się przywrócić dostępność większości serwisów i usług które korzystają z hostingu OVH.
Serwis Wirtualnemedia.pl poprosił OVH o wyjaśnienie przyczyn największej awarii internetu w ostatnich latach. Szczegółowych odpowiedzi udzielił Octave Klaba, CEO OVH w obszernym komunikacie przesłanym do naszej redakcji.
- Dziś rano miał miejsce incydent w sieci światłowodowej, która łączy nasze centrum danych Roubaix (RBX) z 6 z 33 punktów międzynarodowej wymiany ruchu (oP) wchodzącymi w skład naszej sieci szkieletowej: Paryżem (TH2 oraz GSW), Frankfurtem (FRA), Amsterdamem (AMS), Londynem (LDN) i Brukselą (BRU) – wyjaśnia Octave Klaba. - Centrum danych RBX jest połączone za pomocą 6 światłowodów do 6 punktów PoP : 2x RBX<>BRU, 2x RBX<>LDN, 2x RBX<>Paris (1x RBX<>TH2 oraz 1x RBX<>GSW). Te łącza prowadzą do systemu nodów sieciowych, które dają nam 80 długości fal na 100 Gbps w każdym światłowodzie.

Jak tłumaczy szef OVH na każde pasmo 100G podłączone do routerów firma wykorzystuje 2 ścieżki optyczne, które są geograficznie odrębne. W przypadku przerwania światłowodu, na przykład w toku prac ziemnych, system jest ponownie konfigurowany w ciągu 50 ms i wszystkie łącza pozostają aktywne.
- Do połączenia Roubaix z punktami PoP wykorzystujemy przepustowość 4,4TBps, czyli 44 łącza po 100G każde: 12x 100G do Paryża, 8x100G do Londynu, 2x100G do Brukseli, 8x100G do Amsterdamu, 10x100G do Frankfurtu, 2x100G do centrum danych Graveline (GRA) oraz 2x100G do centrum danych w Strasburgu – opisuje Klaba. - O 8:01 nagle wszystkie łącza 100G z 44 dostępnych utraciły połączenie. Biorąc pod uwagę system redundancji, który mamy wdrożony, przyczyną problemu nie mogło być przecięcie wszystkich 6 światłowodów jednocześnie. Nie mogliśmy przeprowadzić diagnostyki zdalnie, ponieważ interfejs zarządzania nie był dostępny. Musieliśmy podjąć więc interwencję w sali routingu, bezpośrednio na urządzeniu sieciowym - odłączyliśmy kable sieciowe, aby zrestartować system i w końcu przeprowadzić diagnostykę z dostawcą urządzeń sieciowych. Próby zrestartowania urządzeń trwały bardzo długo, każde urządzenie uruchamiało się od 10 do 12 minut. To główny czynnik odpowiedzialny za czas trwania awarii. Wszystkie karty transponderów których używamy: ncs2k-400g-lk9, ncs2k-200g-cklc, przeszły w tryb « standby ». Taka sytuacja ma miejsce, gdy zostaje utracona konfiguracja. Przywróciliśmy więc poprzednią konfigurację z kopii zapasowej, dzięki czemu system ponownie skonfigurował wszystkie karty transponderów.
Klaba wyjaśnia, że komunikacja z routerami została przywrócona, a połączenie RBX z sześcioma punktami PoP zostało ponownie ustanowione o godzinie 10:34.
- Powodem awarii jest błąd oprogramowania w urządzeniach sieciowych – ujawnia CEO OVH. - Baza danych z konfiguracją jest rejestrowana trzy razy i kopiowana na dwie karty monitorujące. Mimo wszystkich tych zabezpieczeń baza zniknęła. Będziemy kontynuować współpracę z producentem sprzętu, aby znaleźć przyczynę problemu i doprowadzić do jak najszybszego usunięcia błędu oprogramowania. Nie wycofujemy zaufania, jakim darzymy dostawcę urządzeń, nawet jeżeli ten typ błędu jest szczególnie krytyczny. Wymagana dostępność jest kwestią projektu, który uwzględnia wszystkie przypadki, w tym sytuacje, kiedy wszystko przestaje działać. Tryb ograniczonego zaufania w OVH musi być jeszcze głębiej rozwinięty we wszystkich naszych projektach.
Według Klaby błędy w oprogramowaniu mogą istnieć, ale awarie, które dotykają klientów firmy już nie.
- Najwyraźniej mamy do czynienia z niedociągnięciem po stronie OVH, gdyż mimo istotnych inwestycji w sieć, światłowody, technologie, właśnie doświadczyliśmy dwóch godzin przerwy w usłudze w całej naszej infrastrukturze w Roubaix - przyznaje Klaba. - Jednym z rozwiązań jest stworzenie 2 systemów węzłów światłowodowych zamiast jednego. Oznacza to istnienie dwóch baz danych, co w przypadku utraty konfiguracji spowodowałoby awarię jedynie jednego systemu. Jeśli 50 proc. łączy przechodzi przez jeden z systemów, utracilibyśmy dzisiaj 50 proc. wydajności, nie zaś 100 proc. połączeń. Jest to jeden z projektów, którego realizację rozpoczęliśmy miesiąc temu, urządzenia zostały już zamówione i czekamy na ich dostawę w najbliższych dniach. W ciągu dwóch tygodni będziemy mogli rozpocząć prace konfiguracyjne oraz migrację. Biorąc pod uwagę dzisiejszy incydent, projekt ten staje się dla nas absolutnie priorytetowy w odniesieniu do całości naszej infrastruktury, wszystkich centrów danych i punktów obecności (PoP).
Klaba zaznacza, że w branży dostawców rozwiązań chmurowych jedynie ci, którzy nie ufają nigdy do końca, są odpowiednio zabezpieczeni.
- Jakość usług jest konsekwencją dwóch elementów: wszystkich incydentów wynikających z projektu infrastruktury oraz awarii spowodowanych niedociągnięciami, z których wyciągamy naukę - zapewnia prezes OVH. - Dzisiejszy incydent skłania nas do ustawienia poprzeczki jeszcze wyżej, abyśmy mogli osiągnąć poziom ryzyka bliski zeru. Jest nam niezmiernie przykro z powodu dzisiejszej przerwy w usłudze trwającej 2 godz. 33 minuty w obiekcie w Roubaix. W najbliższych dniach klienci, którzy odczuli negatywne skutki awarii otrzymają wiadomość email dotyczącą naszych zobowiązań SLA - zapowiada Klaba.