Spółka Polskie Badania Czytelnictwa przeprowadziła replikację międzynarodowego badania Europejskiej Unii Nadawców (EBU) pod kierownictwem BBC, aby ocenić jakość polskojęzycznych modeli językowych. Przetestowano po 60 zapytań w modelach ChatGPT, Gemini oraz Perplexity.
Pierwotne badanie wykonano przez testy z udziałem organizacji z 18 krajów, komunikujących się w 14 językach. W badaniu wzięły udział organizacje z Belgii, Wielkiej Brytanii, Kanady, Czechy, Finlandii, Francji, Gruzji, Niemiec, Włoch, Litwy, Holandii, Norwegii, Portugalii, Hiszpanii, Szwecji, Szwajcarii, Ukrainy i Stanów Zjednoczonych.
Profesjonalni dziennikarze uczestniczący w międzynarodowym teście ocenili w 18 krajach blisko 3000 odpowiedzi z serwisów ChatGPT, Copilot, Gemini i Perplexity. Oceniali dokładność, sposób i jakość odniesień do źródeł w streszczaniu informacji, odróżnienie w przedstawianych odpowiedziach opinii od faktów, ujęcie redakcyjne oraz kontekst wypowiedzi, tj. dostarczenie wystarczających informacji lub odpowiednich perspektyw, aby dać czytelnikowi niebędącemu ekspertem kompletną i nie wprowadzającą w błąd odpowiedź.

Badania jednoznacznie dowodzą, że te niedociągnięcia nie są odosobnionymi incydentami. Mają one charakter systemowy, transgraniczny i wielojęzyczny, i naszym zdaniem zagrażają zaufaniu publicznemu. Kiedy ludzie nie wiedzą, komu ufać, w końcu nie ufają niczemu, a to może zniechęcać do uczestnictwa w demokracji
AI zmyśla i błądzi w treściach wydawców
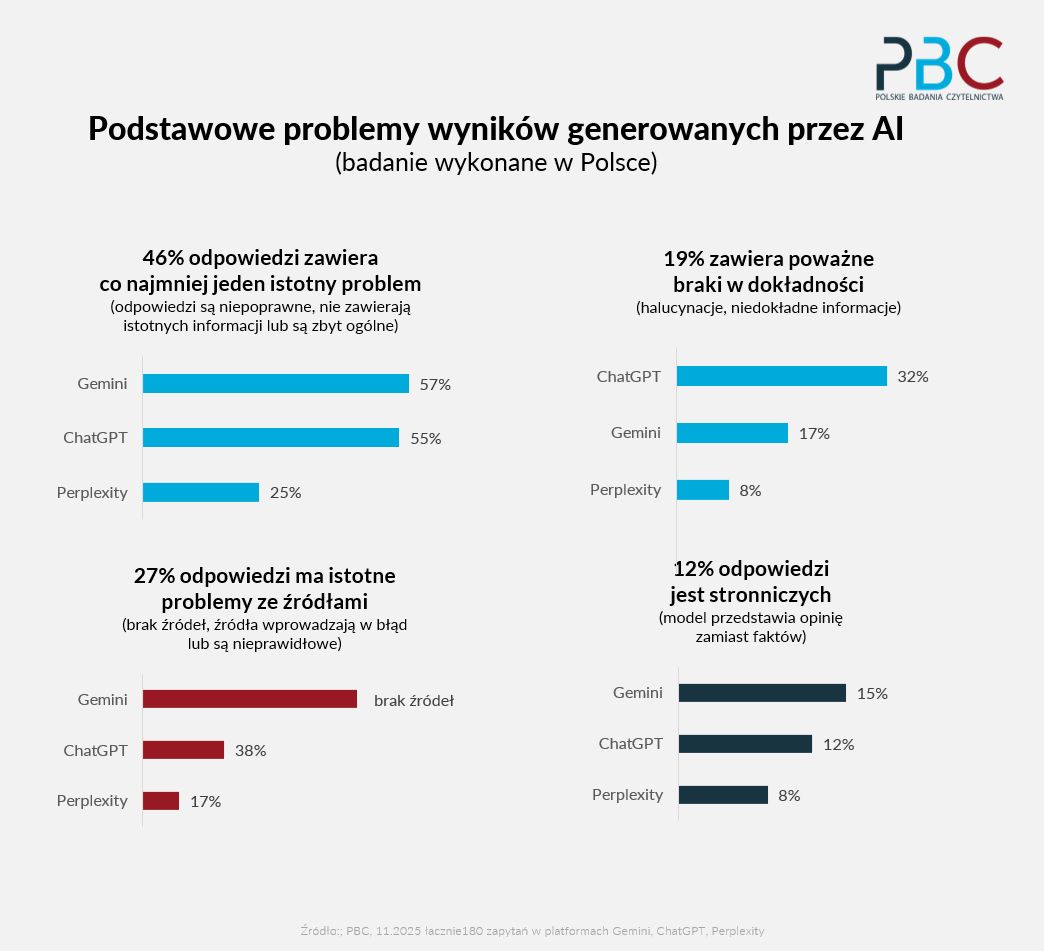
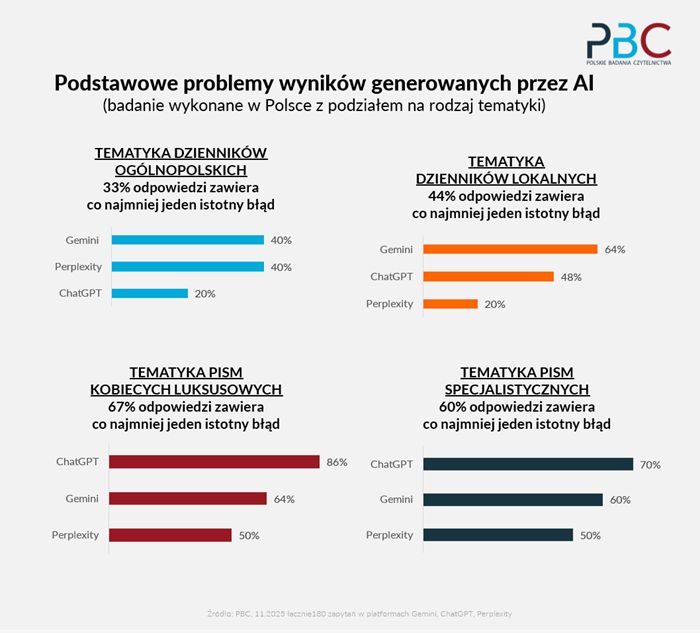
Wyniki testów międzynarodowych i polskich były zbieżne - blisko połowa odpowiedzi sztucznej inteligencji zawiera co najmniej jeden błąd (badania międzynarodowe: 45 proc., badania polskie 46 proc.).
Prawie 1/3 odpowiedzi ma niepoprawnie podane źródła lub ich brak (badania międzynarodowe: 31 proc., badania polskie 27 proc.). Co piąta odpowiedź jest nieprawidłowa, ma poważne błędy w dokładności lub halucynacje (badania międzynarodowe: 20 proc., badania polskie 19 proc.).

Najgorzej w testach wypadł Gemini, model należący do Google. Halucynacje i niedokładne informacje wyłapywano najczęściej w ChatcieGPT.
Asystenci AI, będący już codziennym źródłem informacji dla milionów ludzi, notorycznie przeinaczają treści informacyjne, niezależnie od tego, jaki język, terytorium lub platforma AI są testowane. Badania wskazały, że problem ma charakter systemowy i nie jest związany z językiem, rynkiem ani asystentem AI.
Renata Krzewska, prezes Polski Badań Czytelnictwa: - Mimo przełomowej zmiany, jaka się dokonała w sposobie wyszukiwania informacji, błędy są na tyle poważne, że mogą zagrażać reputacji cytowanych mediów, bo odniesienie w źródłach do renomowanej redakcji czy nazwiska znanego dziennikarza uwiarygadnia podsumowanie, które często nie jest najlepszej jakości.
- Opinie naukowców wskazują, że algorytmy sztucznej inteligencji mogą popełniać błędy, ponieważ niektóre pytania są z natury trudne lub po prostu nie mają uogólnianego wzorca. Błędne odpowiedzi wynikają także ze zwyczajnego przyzwolenie firm technologicznych; gdyby model zbyt często przyznawał się do odpowiedzi "nie wiem", użytkownicy po prostu szukaliby odpowiedzi gdzie indziej - dodaje Krzewska.
Według raportu Digital News Report1 Instytutu Reutersa z 2025 roku, tylko 7 proc. wszystkich odbiorców wiadomości online intencjonalnie korzysta z asystentów AI, w szczególności z ChatGPT, Gemini czy Perplexity. Wśród osób poniżej 25. roku życia odsetek ten wzrasta do 15 proc.